Co-reporter:J. Engel, L. Blanchet, B. Bloemen, L.P. van den Heuvel, U.H.F. Engelke, R.A. Wevers, L.M.C. Buydens
Analytica Chimica Acta 2015 Volume 899() pp:1-12
Publication Date(Web):29 October 2015
DOI:10.1016/j.aca.2015.06.042
•MANOVA and ASCA have serious drawbacks for analysis of experimental designs.•We propose regularized MANOVA (rMANOVA) for analysis of such data.•rMANOVA is a weighted average of the ASCA and MANOVA models.•Thus the best properties of both models are combined and their pitfalls avoided.•rMANOVA is used to analyze data of a metabolomics nutritional intervention study.Many advanced metabolomics experiments currently lead to data where a large number of response variables were measured while one or several factors were changed. Often the number of response variables vastly exceeds the sample size and well-established techniques such as multivariate analysis of variance (MANOVA) cannot be used to analyze the data.ANOVA simultaneous component analysis (ASCA) is an alternative to MANOVA for analysis of metabolomics data from an experimental design. In this paper, we show that ASCA assumes that none of the metabolites are correlated and that they all have the same variance. Because of these assumptions, ASCA may relate the wrong variables to a factor. This reduces the power of the method and hampers interpretation.We propose an improved model that is essentially a weighted average of the ASCA and MANOVA models. The optimal weight is determined in a data-driven fashion. Compared to ASCA, this method assumes that variables can correlate, leading to a more realistic view of the data. Compared to MANOVA, the model is also applicable when the number of samples is (much) smaller than the number of variables. These advantages are demonstrated by means of simulated and real data examples. The source code of the method is available from the first author upon request, and at the following github repository: https://github.com/JasperE/regularized-MANOVA.
Co-reporter:Jan P. M. Andries, Yvan Vander Heyden, and Lutgarde M. C. Buydens
Analytical Chemistry 2013 Volume 85(Issue 11) pp:5444
Publication Date(Web):May 2, 2013
DOI:10.1021/ac400339e
For partial least-squares regression with one response (PLS1), many variable-reduction methods have been developed. However, only a few address the case of multiple-response partial-least-squares (PLS2) modeling. The calibration performance of PLS1 can be improved by elimination of uninformative variables. Many variable-reduction methods are based on various PLS-model-related parameters, called predictor-variable properties. Recently, an important adaptation, in which the model complexity is optimized, was introduced in these methods. This method was called Predictive-Property-Ranked Variable Reduction with Final Complexity Adapted Models, denoted as PPRVR-FCAM or simply FCAM. In this study, variable reduction for PLS2 models, using an adapted FCAM method, FCAM-PLS2, is investigated. The utility and effectiveness of four new predictor-variable properties, derived from the multiple response PLS2 regression coefficients, are studied for six data sets consisting of ultraviolet–visible (UV–vis) spectra, near-infrared (NIR) spectra, NMR spectra, and two simulated sets, one with correlated and one with uncorrelated responses. The four properties include the mean of the absolute values as well as the norm of the PLS2 regression coefficients and their significances. The four properties were found to be applicable by the FCAM-PLS2 method for variable reduction. The predictive abilities of models resulting from the four properties are similar. The norm of the PLS2 regression coefficients has the best selective abilities, low numbers of variables with an informative meaning to the responses are retained. The significance of the mean of the PLS2 regression coefficients is found to be the least-selective property.
Co-reporter:Tom G. Bloemberg, Hans J. C. T. Wessels, Maurice van Dael, Jolein Gloerich, Lambert P. van den Heuvel, Lutgarde M. C. Buydens, and Ron Wehrens
Analytical Chemistry 2011 Volume 83(Issue 13) pp:5197
Publication Date(Web):May 10, 2011
DOI:10.1021/ac200334s
The identification of differential patterns in data originating from combined measurement techniques such as LC/MS is pivotal to proteomics. Although “shotgun proteomics” has been employed successfully to this end, this method also has severe drawbacks, because of its dependence on largely untargeted MS/MS sequencing and databases for statistical analyses. Alternatively, several MS-signal-based (MS/MS-independent) methods have been published that are mainly based on (univariate) Student’s t-tests. Here, we present a more robust multivariate alternative employing linear discriminant analysis. Like the t-test-based methods, it is applied directly to LC/MS data, instead of using MS/MS measurements. We demonstrate the method on a number of simulated data sets, as well as on a spike-in LC/MS data set, and show its superior performance over t-tests.
Co-reporter:Jan P.M. Andries, Yvan Vander Heyden, Lutgarde M.C. Buydens
Analytica Chimica Acta 2011 Volume 705(1–2) pp:292-305
Publication Date(Web):31 October 2011
DOI:10.1016/j.aca.2011.06.037
The calibration performance of partial least squares for one response variable (PLS1) can be improved by elimination of uninformative variables. Many methods are based on so-called predictive variable properties, which are functions of various PLS-model parameters, and which may change during the variable reduction process. In these methods variable reduction is made on the variables ranked in descending order for a given variable property. The methods start with full spectrum modelling. Iteratively, until a specified number of remaining variables is reached, the variable with the smallest property value is eliminated; a new PLS model is calculated, followed by a renewed ranking of the variables. The Stepwise Variable Reduction methods using Predictive-Property-Ranked Variables are denoted as SVR-PPRV. In the existing SVR-PPRV methods the PLS model complexity is kept constant during the variable reduction process. In this study, three new SVR-PPRV methods are proposed, in which a possibility for decreasing the PLS model complexity during the variable reduction process is build in.Therefore we denote our methods as PPRVR-CAM methods (Predictive-Property-Ranked Variable Reduction with Complexity Adapted Models). The selective and predictive abilities of the new methods are investigated and tested, using the absolute PLS regression coefficients as predictive property. They were compared with two modifications of existing SVR-PPRV methods (with constant PLS model complexity) and with two reference methods: uninformative variable elimination followed by either a genetic algorithm for PLS (UVE-GA-PLS) or an interval PLS (UVE-iPLS). The performance of the methods is investigated in conjunction with two data sets from near-infrared sources (NIR) and one simulated set. The selective and predictive performances of the variable reduction methods are compared statistically using the Wilcoxon signed rank test.The three newly developed PPRVR-CAM methods were able to retain significantly smaller numbers of informative variables than the existing SVR-PPRV, UVE-GA-PLS and UVE-iPLS methods without loss of prediction ability. Contrary to UVE-GA-PLS and UVE-iPLS, there is no variability in the number of retained variables in each PPRV(R) method. Renewed variable ranking, after deletion of a variable, followed by remodelling, combined with the possibility to decrease the PLS model complexity, is beneficial. A preferred PPRVR-CAM method is proposed.Graphical abstractHighlights► Three new variable reduction methods were developed, called Predictive-Property-Ranked Variable Reduction with Complexity Adapted Models (PPRVR-CAM) methods. ► PPRVR-CAM methods have a possibility for decreasing the PLS model complexity during variable reduction. ► The methods are able to retain significantly smaller numbers of informative variables than the existing methods based on predictive-property-ranked variables, UVE-GA-PLS and UVE-iPLS, without loss of prediction ability. ► Important variables, with a chemical meaning relevant to the response, are not excluded in the stepwise backward variable selection procedures.
Co-reporter:G.J. Postma, P.W.T. Krooshof, L.M.C. Buydens
Analytica Chimica Acta 2011 Volume 705(1–2) pp:123-134
Publication Date(Web):31 October 2011
DOI:10.1016/j.aca.2011.04.025
Kernel partial least squares (KPLS) and support vector regression (SVR) have become popular techniques for regression of complex non-linear data sets. The modeling is performed by mapping the data in a higher dimensional feature space through the kernel transformation. The disadvantage of such a transformation is, however, that information about the contribution of the original variables in the regression is lost. In this paper we introduce a method which can retrieve and visualize the contribution of the variables to the regression model and the way the variables contribute to the regression of complex data sets. The method is based on the visualization of trajectories using so-called pseudo samples representing the original variables in the data. We test and illustrate the proposed method to several synthetic and real benchmark data sets. The results show that for linear and non-linear regression models the important variables were identified with corresponding linear or non-linear trajectories. The results were verified by comparing with ordinary PLS regression and by selecting those variables which were indicated as important and rebuilding a model with only those variables.Graphical abstractHighlights► We provide a solution to visualize the contribution of variables to kernel based regression methods. ► This variable information is lost in methods like KPLS and support vector regression due to the kernel. ► The influence and non-linearity of the variables are visualized using so-called pseudo sample trajectories. ► We have tested the method on several artificial and real linear and non-linear data sets. ► Our method clearly indicates the important variables.
Co-reporter:Agnieszka Smolinska, Amos Attali, Lionel Blanchet, Kirsten Ampt, Tinka Tuinstra, Hans van Aken, Ernst Suidgeest, Alain J. van Gool, Theo Luider, Sybren S. Wijmenga, and Lutgarde M.C. Buydens
Journal of Proteome Research 2011 Volume 10(Issue 10) pp:4428-4438
Publication Date(Web):2017-2-22
DOI:10.1021/pr200203v
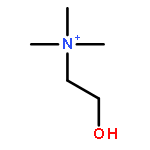
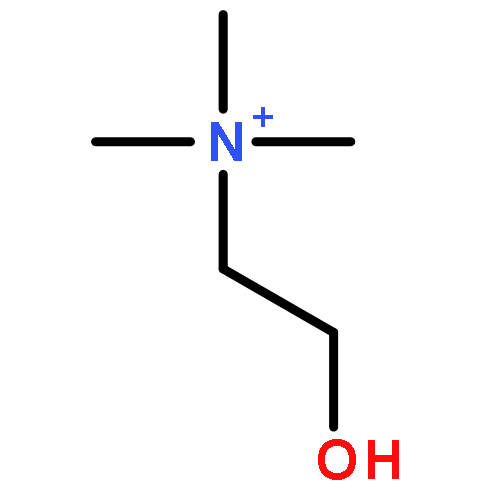
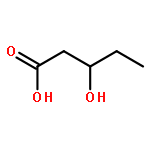
Multiple Sclerosis (MScl) is a neurodegenerative disease of the CNS, associated with chronic neuroinflammation. Cerebrospinal fluid (CSF), being in closest interaction with CNS, was used to profile neuroinflammation to discover disease-specific markers. We used the commonly accepted animal model for the neuroinflammatory aspect of MScl: the experimental autoimmune/allergic encephalomyelitis (EAE). A combination of advanced 1H NMR spectroscopy and pattern recognition methods was used to establish the metabolic profile of CSF of EAE-affected rats (representing neuroinflammation) and of two control groups (healthy and peripherally inflamed) to detect specific markers for early neuroinflammation. We found that the CSF metabolic profile for neuroinflammation is distinct from healthy and peripheral inflammation and characterized by changes in concentrations of metabolites such as creatine, arginine, and lysine. Using these disease-specific markers, we were able to detect early stage neuroinflammation, with high accuracy in a second independent set of animals. This confirms the predictive value of these markers. These findings from the EAE model may help to develop a molecular diagnosis for the early stage MScl in humans.
Co-reporter:Patrick W. T. Krooshof, Bülent Üstün, Geert J. Postma and Lutgarde M. C. Buydens
Analytical Chemistry 2010 Volume 82(Issue 16) pp:7000
Publication Date(Web):July 20, 2010
DOI:10.1021/ac101338y
Support vector machines (SVMs) have become a popular technique in the chemometrics and bioinformatics field, and other fields, for the classification of complex data sets. Especially because SVMs are able to model nonlinear relationships, the usage of this technique has increased substantially. This modeling is obtained by mapping the data in a higher-dimensional feature space. The disadvantage of such a transformation is, however, that information about the contribution of the original variables in the classification is lost. In this paper we introduce an innovative method which can retrieve the information about the variables of complex data sets. We apply the proposed method to several benchmark data sets and a metabolomics data set to illustrate that we can determine the contribution of the original variables in SVM classifications. The corresponding visualization of the contribution of the variables can assist in a better understanding of the underlying chemical or biological process.
Co-reporter:Guro F. Giskeødegård, Tom G. Bloemberg, Geert Postma, Beathe Sitter, May-Britt Tessem, Ingrid S. Gribbestad, Tone F. Bathen, Lutgarde M.C. Buydens
Analytica Chimica Acta 2010 Volume 683(Issue 1) pp:1-11
Publication Date(Web):17 December 2010
DOI:10.1016/j.aca.2010.09.026
The peaks of magnetic resonance (MR) spectra can be shifted due to variations in physiological and experimental conditions, and correcting for misaligned peaks is an important part of data processing prior to multivariate analysis. In this paper, five warping algorithms (icoshift, COW, fastpa, VPdtw and PTW) are compared for their feasibility in aligning spectral peaks in three sets of high resolution magic angle spinning (HR-MAS) MR spectra with different degrees of misalignments, and their merits are discussed. In addition, extraction of information that might be present in the shifts is examined, both for simulated data and the real MR spectra. The generic evaluation methodology employs a number of frequently used quality criteria for evaluation of the alignments, together with PLS-DA to assess the influence of alignment on the classification outcome.Peak alignment greatly improved the internal similarity of the data sets. Especially icoshift and COW seem suitable for aligning HR-MAS MR spectra, possibly because they perform alignment segment-wise. The choice of reference spectrum can influence the alignment result, and it is advisable to test several references. Information from the peak shifts was extracted, and in one case cancer samples were successfully discriminated from normal tissue based on shift information only. Based on these findings, general recommendations for alignment of HR-MAS MRS data are presented. Where possible, observations are generalized to other data types (e.g. chromatographic data).
Co-reporter:Jan P.M. Andries, Henk A. Claessens, Yvan Vander Heyden, Lutgarde M.C. Buydens
Analytica Chimica Acta 2009 Volume 652(1–2) pp:180-188
Publication Date(Web):12 October 2009
DOI:10.1016/j.aca.2009.06.019
In high-performance liquid chromatography, quantitative structure–retention relationships (QSRRs) are applied to model the relation between chromatographic retention and quantities derived from molecular structure of analytes. Classically a substantial number of test analytes is used to build QSRR models. This makes their application laborious and time consuming. In this work a strategy is presented to build QSRR models based on selected reduced calibration sets. The analytes in the reduced calibration sets are selected from larger sets of analytes by applying the algorithm of Kennard and Stone on the molecular descriptors used in the QSRR concerned. The strategy was applied on three QSRR models of different complexity, relating log kwlog kw or log k with either: (i) log P, the n-octanol–water partition coefficient, (ii) calculated quantum chemical indices (QCI), or (iii) descriptors from the linear solvation energy relationship (LSER). Models were developed and validated for 76 reversed-phase high-performance liquid chromatography systems.From the results we can conclude that it is possible to develop log P models suitable for the future prediction of retentions with as few as seven analytes. For the QCI and LSER models we derived the rule that three selected analytes per descriptor are sufficient. Both the dependent variable space, formed by the retention values, and the independent variable space, formed by the descriptors, are covered well by the reduced calibration sets. Finally guidelines to construct small calibration sets are formulated.
Co-reporter:J. Brs;C. Geurts;R. Huo;R. Wehrens;Professor L. M. C. Buydens
Magnetic Resonance in Chemistry 2006 Volume 44(Issue 2) pp:110-117
Publication Date(Web):15 DEC 2005
DOI:10.1002/mrc.1721
MULVADO is a newly developed software package for DOSY NMR data processing, based on multivariate curve resolution (MCR), one of the principal multivariate methods for processing DOSY data. This paper will evaluate this software package by using real-life data of materials used in the printing industry: two data sets from the same ink sample but of different quality. Also a sample of an organic photoconductor and a toner sample are analysed. Compared with the routine DOSY output from monoexponential fitting, one of the single channel algorithms in the commercial Bruker software, MULVADO provides several advantages. The key advantage of MCR is that it overcomes the fluctuation problem (non-consistent diffusion coefficient of the same component). The combination of non-linear regression (NLR) and MCR can yield more accurate resolution of a complex mixture. In addition, the data pre-processing techniques in MULVADO minimise the negative effects of experimental artefacts on the results of the data. In this paper, the challenges for analysing polymer samples and other more complex samples will also be discussed. Copyright © 2005 John Wiley & Sons, Ltd.
Co-reporter:Thanh N. Tran;Ron Wehrens;Lutgarde M. C. Buydens
Journal of Chemometrics 2005 Volume 19(Issue 11‐12) pp:607-614
Publication Date(Web):1 JUN 2006
DOI:10.1002/cem.966
SMIXTURE, a novel strategy for mixture model clustering of multivariate images, has been developed. Most other clustering approaches require good guesses of the number of components (clusters) and the initial statistical parameters. In our approach, the initial parameters are determined by agglomerative clustering on homogenous regions, identified by region growing segmentation. SMIXTURE can be used in both a normal situation of mixture modeling, where the density of a cluster is modeled by a single normal distribution; and in a more complex situation, where the density of a single cluster is a mixture of several normal sub-clusters. The method has proven to be very robust to noise/outliers, overlapping clusters, is reasonably fast and is suitable for moderate to large images. Copyright © 2006 John Wiley & Sons, Ltd.
Co-reporter:U. Thissen;H. Swierenga;A. P. de Weijer;R. Wehrens;W. J. Melssen
Journal of Chemometrics 2005 Volume 19(Issue 1) pp:23-31
Publication Date(Web):4 JUL 2005
DOI:10.1002/cem.903
When performing process monitoring, the classical approach of multivariate statistical process control (MSPC) explicitly assumes the normal operating conditions (NOC) to be distributed normally. If this assumption is not met, usually severe out-of-control situations are missed or in-control situations can falsely be seen as out-of-control. Combining mixture modelling with MSPC (MM-MSPC) leads to an approach in which non-normally distributed NOC regions can be described accurately. Using the expectation maximization (EM) algorithm, a mixture of Gaussian functions can be defined that, together, describe the data well. Using the Bayesian information criterion (BIC), the optimal set of Gaussians and their specific parametrization can be determined easily. Artificial and industrial data sets have been used to test the performance of the combined MM-MSPC approach. From these applications it has been shown that MM-MSPC is very promising: (1) a better description of the process data is given compared with standard MSPC and (2) the clusters found can be used for a more detailed process analysis and interpretation. Copyright © 2005 John Wiley & Sons, Ltd.
Co-reporter:Jasper Engel, Jan Gerretzen, Ewa Szymańska, Jeroen J. Jansen, Gerard Downey, Lionel Blanchet, Lutgarde M.C. Buydens
TrAC Trends in Analytical Chemistry (October 2013) Volume 50() pp:96-106
Publication Date(Web):October 2013
DOI:10.1016/j.trac.2013.04.015